

发布日期:2023-10-30 04:49 点击次数:64

[[436012]]亚博在线

在粉丝群内部,我屡次强调爬虫不要把网页源代码存入数据库,但依然有许多同学这么作念。源代码动辄几十 KB 致使几 MB,存放到数据库内部会严重拖慢性能。
南沙巴士公司表示后续会陆续推出优惠套票活动(“一站式”购票,优惠多多),可关注“如约城际巴士”或“南沙巴士”公众号发布的相关信息,也可在南沙巴士公众号中购票和查询上下站点、车次等信息。
如若你非要储存源代码,那么你不错使用 Hive 或者对象储存来存放。
如若你必不得已,必须用数据库来存放,那么你至少应该对HTML 进行压缩。普通咱们不竭传说使用 winrar/7zip/tar 这些压缩器用来压缩文献或者文献夹,那么咱们怎么压缩字符串呢?
洗码Python 自带了两种压缩面目:zlib和gzip。
咱们先来望望我的博客首页有多大:
zh皇冠登3代理出租import requests html = requests.get('https://www.kingname.info').text with open('kingname.html', 'w') as f: f.write(html)
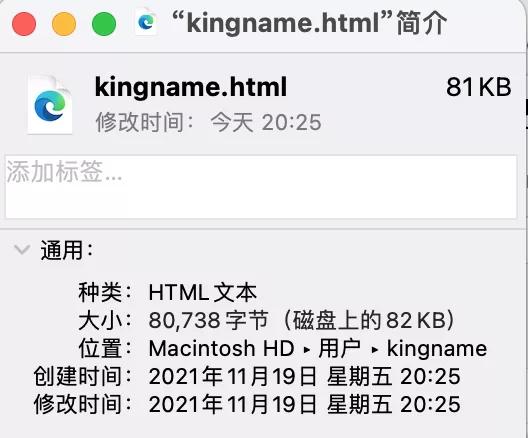
生成的kingname.html文献,有82KB,如下图所示:
当今,咱们使用zlib来对 HTML 进行压缩,然后把压缩后的实质写到文献,咱们来望望数据有多大:
皇冠客服飞机:@seo3687import zlib import requests html = requests.get('https://www.kingname.info').text html_compressed = zlib.compress(html.encode()) with open('kingname_zlib', 'wb') as f: f.write(html_compressed)
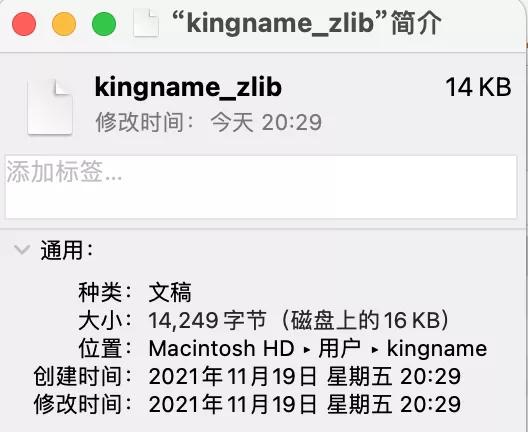
生成的文献大小惟有16KB,如下图所示:
压缩以后体积造成了底本的五分之一,大致了大王人的磁盘空间。需要看重的是,欧博开户网址zlib.compress的输入参数是bytes型的数据,输出亦然bytes型的数据。况兼,输出的数据是不行解码成字符串的,是以在写文献的时代,必须使用wb面目写入。如若你用的 MySQL 的话,需要把字段的类型开导成blob。
bet365是哪个国家的要解压缩也至极浅易,使用zlib.decompress就不错了:
import zlib with open('kingname_zlib', 'rb') as f: html_compressed = f.read() html = zlib.decompress(html_compressed).decode()
除了zlib外,咱们还不错使用gzip这个自带的模块来压缩字符串。用法险些一模同样:
import gzip import requests html = requests.get('https://www.kingname.info').text html_compressed = gzip.compress(html.encode()) with open('kingname_gzip', 'wb') as f: f.write(html_compressed)
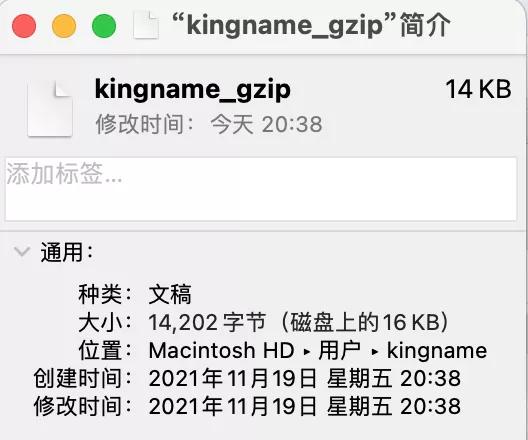
压缩以后,文献大小亦然16KB:
最近,有传闻称博彩巨头皇冠体育正在与体育明星梅西洽谈代言事宜。据悉,这次合作将为梅西带来数百万美元的收入,同时也将让皇冠体育更进一步扩大自己的品牌影响力。皇冠hg86a
在坐褥表情中,除了Python自带的这两个压缩模块,还有可能会使用Snappy进行压缩。他的压缩速率至极快,比zlib和gzip王人快。压缩率也很高。但安设起来相比弯曲,率先需要安设Snappy智商,然后再安设python-snappy库武艺使用。有艳羡的同学不错搜索了解一下。
记忆:激烈不提倡使用数据库来存放网页整个这个词源代码。如若非要使用亚博在线,要压缩以后再存。
